
最近,我正在读《深入浅出数据分析》这本书。
上期跟大家分享的书中主题是「 如何减小合理误差? 」。
今天,我来聊聊「关系数据库」。
一张电子数据表只有两维数据:行和列。
如果你的数据表包括许多方面,则表格格式很快就会过时。
电子表格很难管理多变量数据。
关系数据库管理系统让多变量数据的存储和检索变得极其简单。
一、分析销量
1、案例背景:《数据邦新闻》希望把每期杂志的文章数量与销量关联起来,然后找出在每一期刊物上刊登文章的最优数量。
2、你需要知道数据表之间的关系。为了得到想要的答案,你创建表格,据此将文章数目和销量联系起来。因此你需要知道这些表格如何相互关联。

3、用箭头和文字说明每张数据表中记录的数据之间的关系。
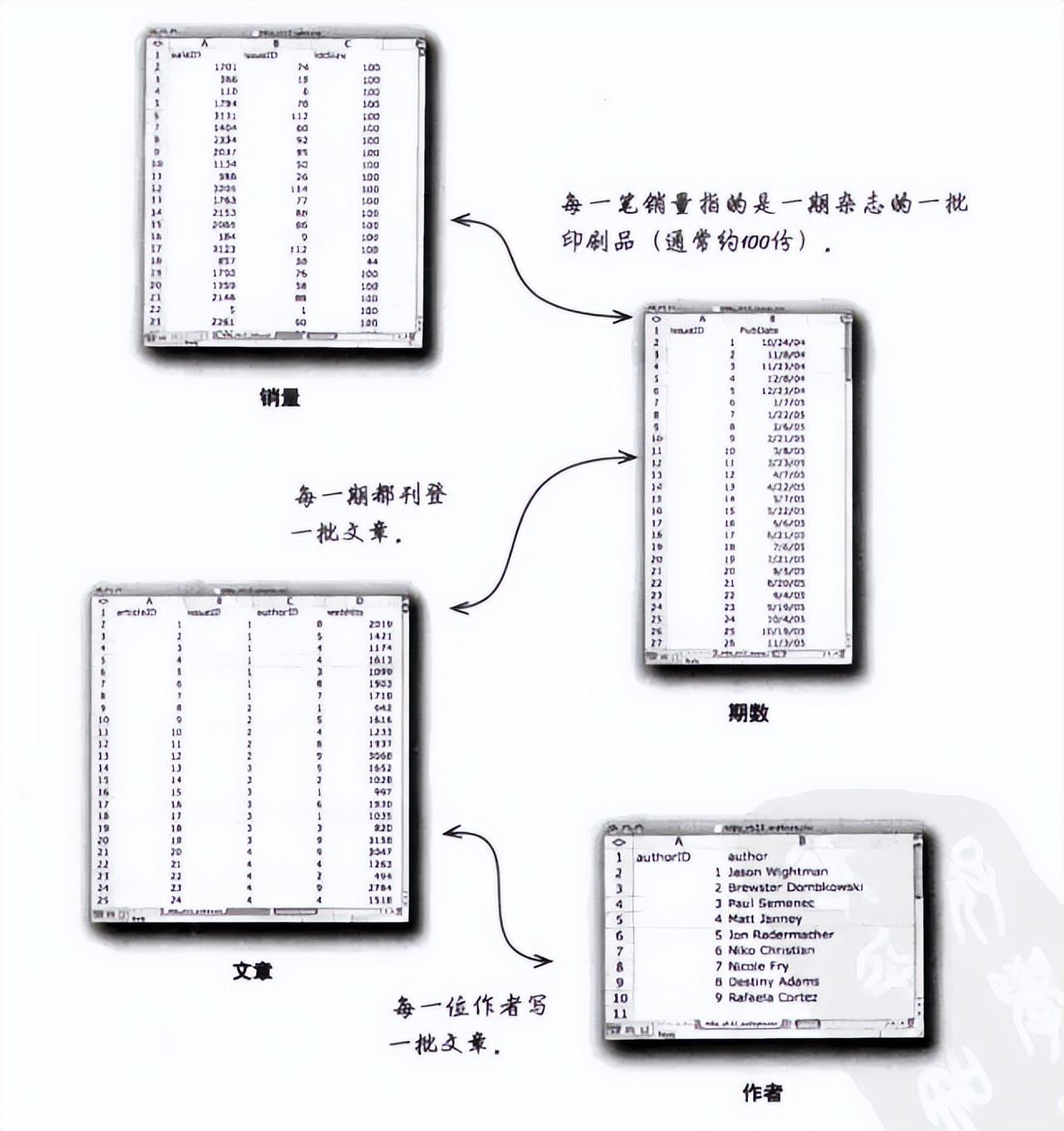
二、数据库
1、数据库就是一系列相互有特定关系的数据。一个数据库就是一张表格或一组表格,表格以某种方式对数据进行管理,使数据之间的相互关系显而易见。
2、如果手头有一些相互独立的表格,但这些表格中的数据互有关系,同时又有一个关系到多张表格的问题需要解答,那么,就需要沿着相互关联的表格顺藤摸瓜。
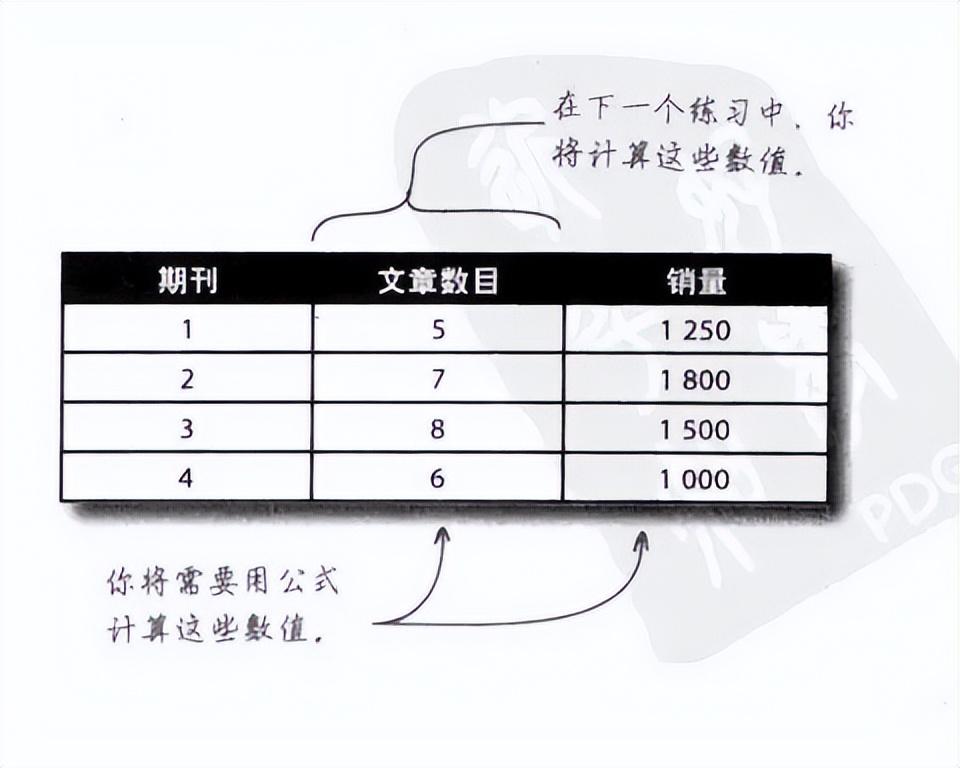
3、创建一份穿过这条路径的电子表格。在本例中,你需要有一份能对每期文章数目和销量进行比较的表格。你需要写出公式,以便计算需要计算的数值。
4、表格下载地址:
https://resources.oreilly.com/examples/9780596153946/-/blob/master/hfda_ch12_issues.csv
https://resources.oreilly.com/examples/9780596153946/-/blob/master/hfda_ch12_articles.csv
https://resources.oreilly.com/examples/9780596153946/-/blob/master/hfda_ch12_sales.csv
5、打开“hfda_ch12_issues.csv”文件,另存为一份副本,以便工作。记住,可别把原始文件搞乱了!将新文件取名为“dispatch analysis.xls”。
6、打开“hfda_ch12_articles.csv”文件,将表格复制到“dispatch analysis.xls”文档中。
7、创建文章数目(article count)列,填入“countif”公式计算该期刊的文章数目;然后对每一期刊物复制和粘贴该公式。
=COUNTIF(hfda_ch12_articles!B:B,A2)
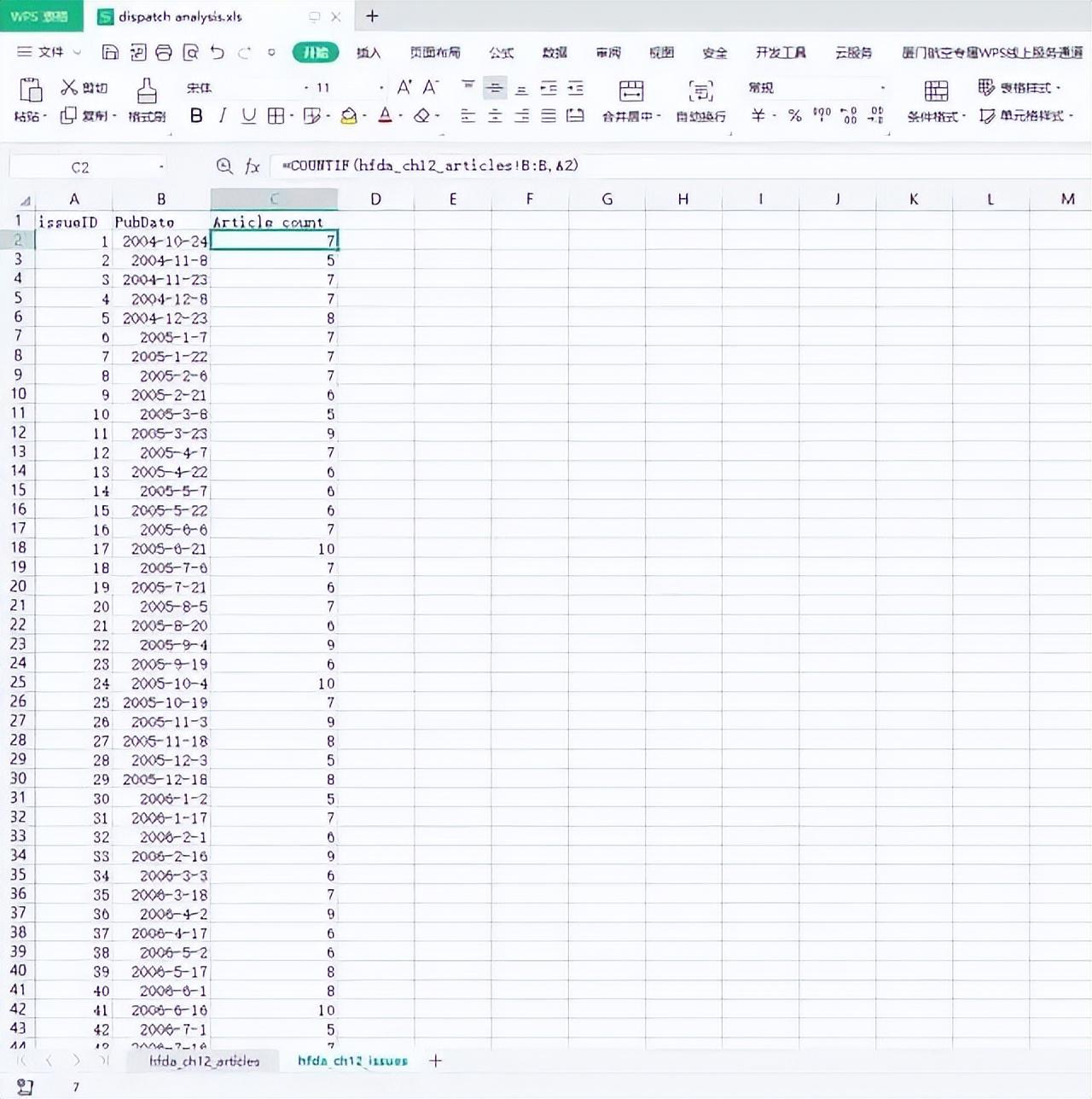
计算每一期刊物出现在文章列表中的次数
8、复制hfda_ch12_sales.csv文件,使其成为dispatch analysis.xls中的一个新选项卡。在用于计算文章数目的同一个工作表中,新建一个Sales(销量)列。
9、使用SUMIF公式计算期刊ID1(issueID 1)的销量数据,将公式填写在单元格C2中。复制该公式,为其余每一期刊物粘贴该公式。
=SUMIF(hfda_ch12_sales!B:B,A2,hfda_ch12_sales!C:C)
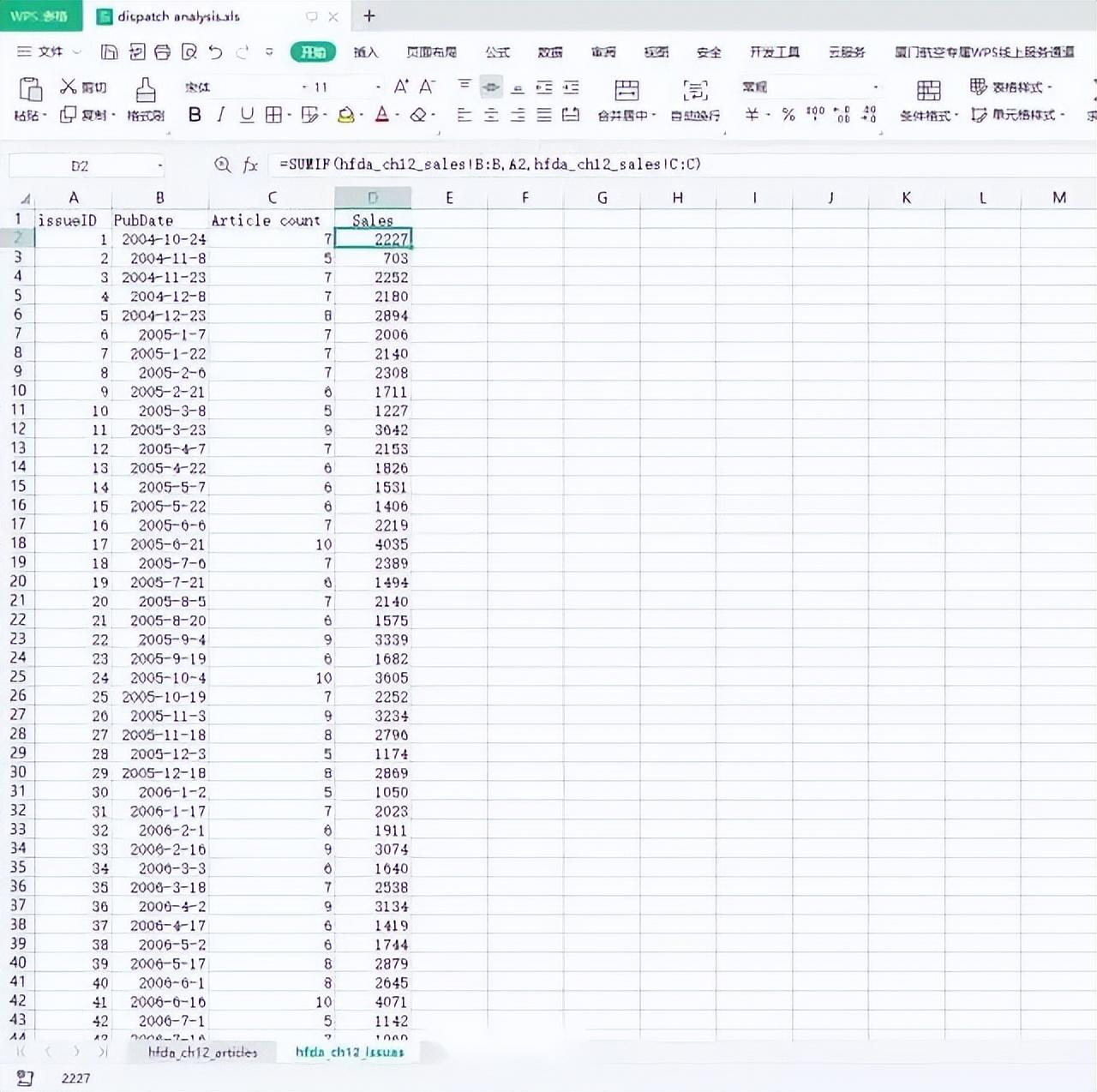
10、通过汇总将文章数目和销量关联起来,表明了《新闻》每一期刊登的文章数目与期刊销量之间的关系。
三、用R软件画散点图
1、打开R,输入getwd()指令,求出R保存数据的位置。
getwd()
2、将电子表格“dispatch analysis.xls”在该目录下另存为CSV文件。
3、执行下列指令,将数据加载到R中。
dispatch <- read.csv("dispatch analysis.csv",header = TRUE)4、加载数据后,执行下列函数。
plot(Sales~jitter(Article.count),data = dispatch)
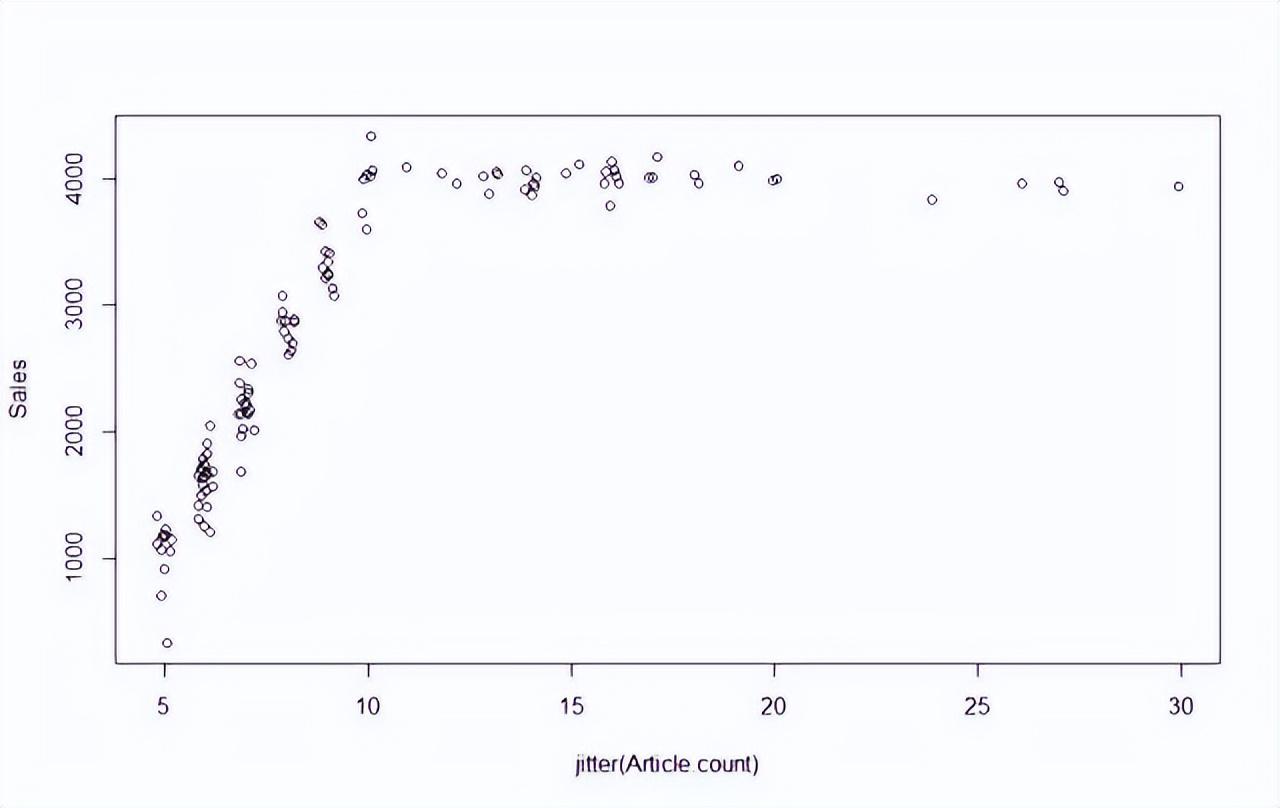
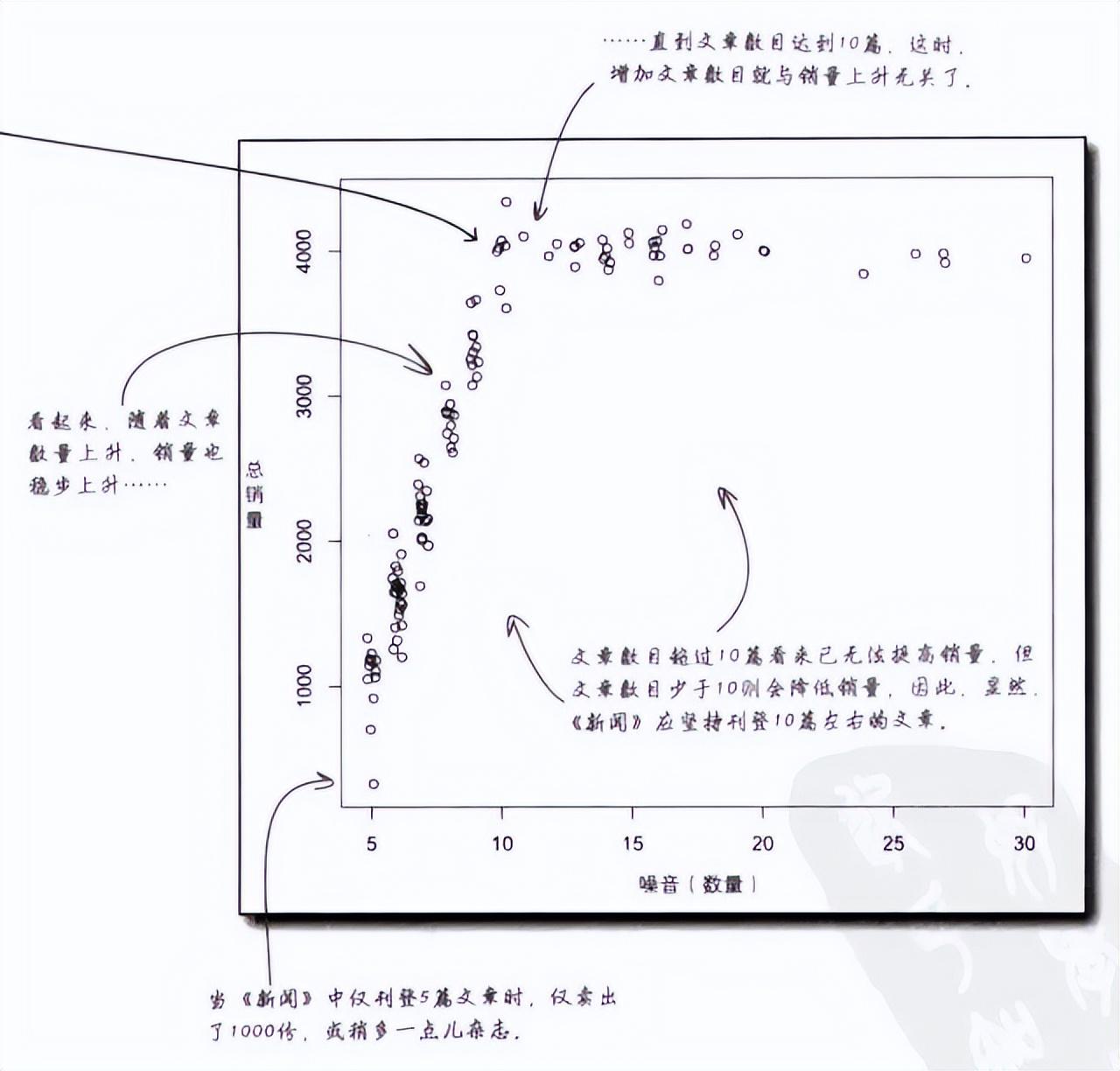
5、jitter指令在数字中添加了一些噪音,使数据相互分隔,以便易于在散点图上识别。

6、最优值似乎在10篇文章左右。随着文章数量上升,销量也稳步上升,直到文章数目达到10篇时,增加文章数目就与销量上升无关了。因此,显然《新闻》应坚持刊登10篇左右的文章。
四、用关系数据库管理关系
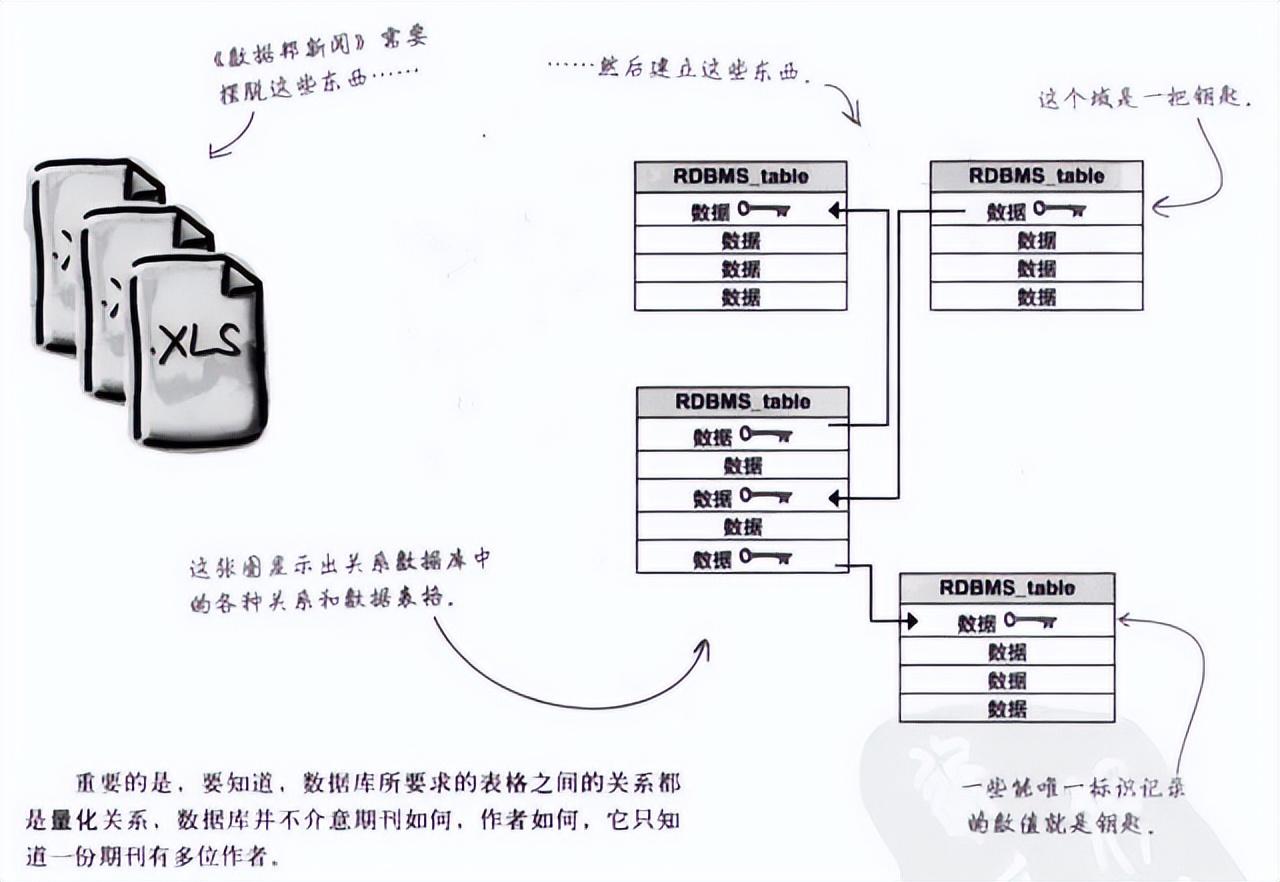
1、关系数据库管理系统(RDBMS)是最重要最有效的数据管理方法之一。
2、RDBMS中的每一行都有一把钥匙,通常成为ID(标识),钥匙可以确保这些量化关系不被破坏。
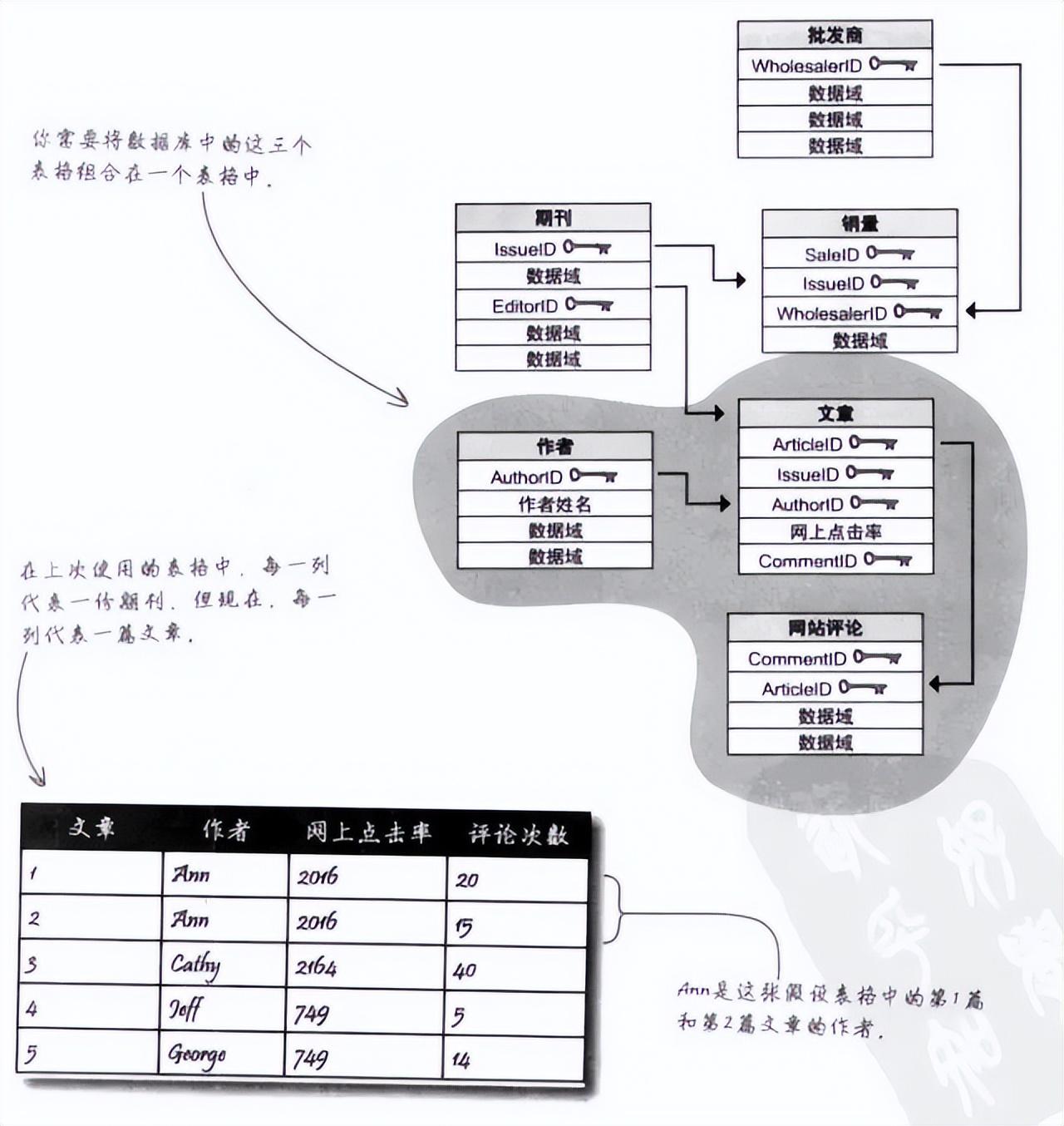
3、为了计算某个作者在网上的点击率和评价情况,以便以此评估作者的受欢迎程度,需要把三个表格组合在一起。
五、用SQL提取数据
1、SQL是Structure Query Language的缩写,即结构化查询语言,是一种关系数据库检索方法。
2、你可以通过输入代码或使用能创建SQL代码的图形界面,令数据库回答你的SQL问题。
3、你并不是非懂SQL不可,但懂得SQL绝不是坏事。重要的是,了解数据库中的各个表格及这些表格的相互关系,进而懂得如何提出正确的问题。
4、表格下载地址:
https://resources.oreilly.com/examples/9780596153946/-/blob/master/hfda_ch12_articleHitsComments.csv
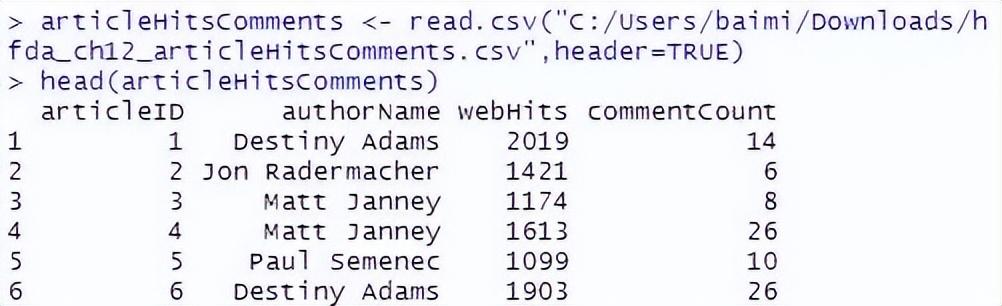
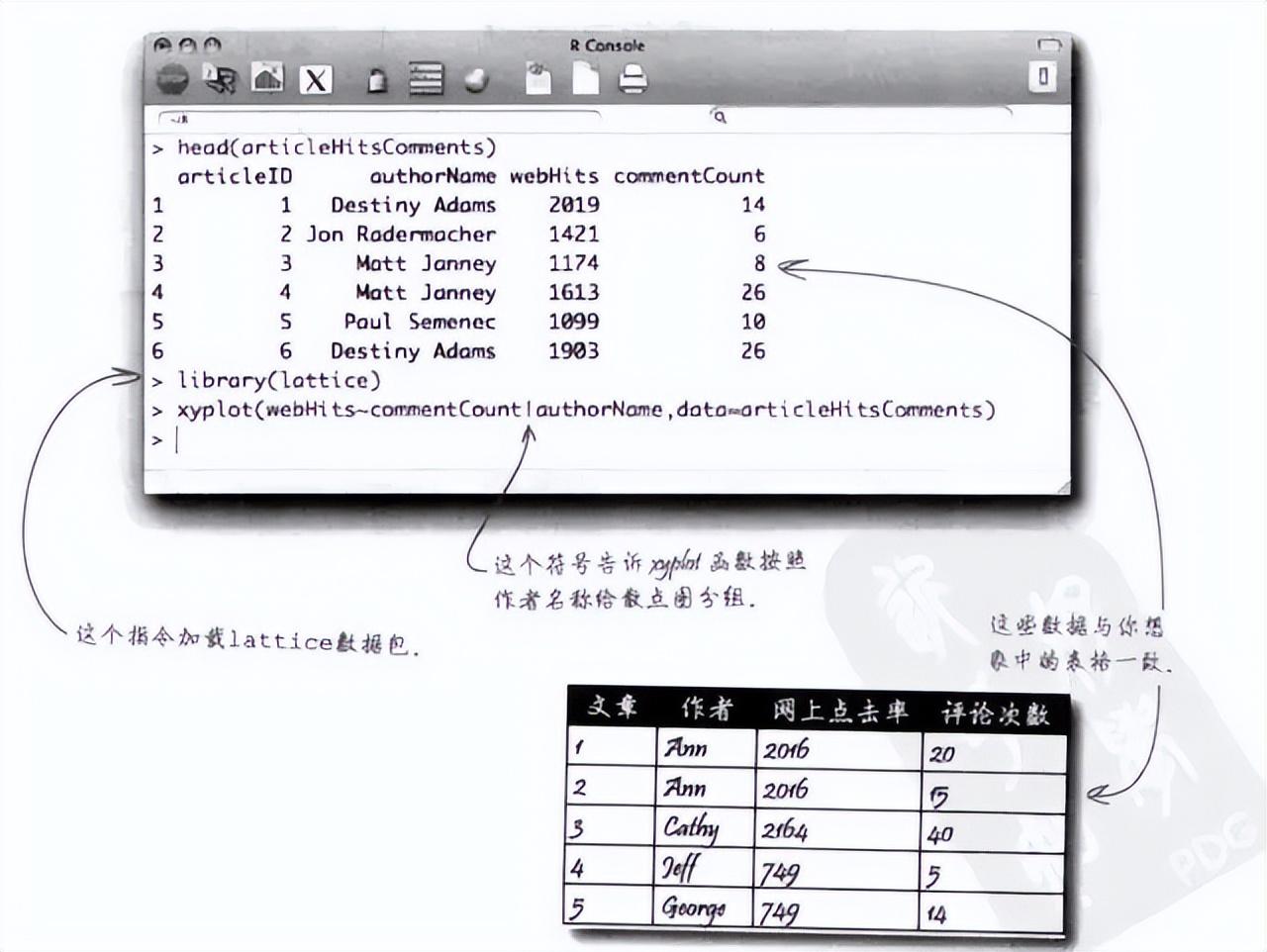
5、使用下面的指令将“hfda_ch12_articleHitsComments.csv”电子表格加载到R软件中,然后用head指令查看数据。
articleHitsComments <- read.csv("C:/Users/baimi/Downloads/hfda_ch12_articleHitsComments.csv",header=TRUE)
head(articleHitsComments)
6、这次我们将用更有效的函数创建散点图。用下面这些指令加载“lattice”数据包,然后运行xyplot公式,绘制lattice散点图。
library(lattice)
xyplot(webHits~commentCount|authorName,data = articleHitsComments)
7、这个散点图集合显示出每篇文章的网站点击率和评论次数,并按作者分组。这些网络统计值分布在各个图上,但每位作者的表现各不相同。
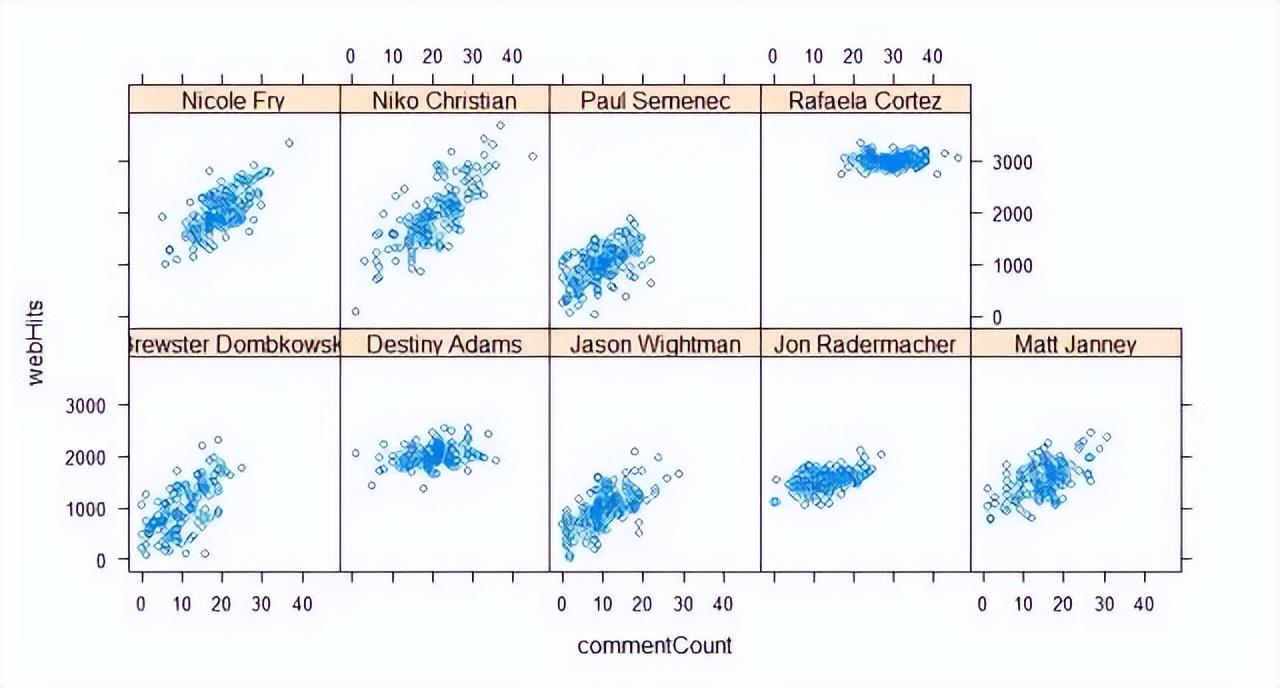
8、很明显,Rafaela的表现最好,所有的文章点击率都在3000以上,且大部分文章都有20多篇评论,看来人们真的很喜欢。其他作者的表现有好有坏,Destiny和Nicole表现较好,Niko的表现数据很散,而Brewster和Jason则显得不太受欢迎。
9、RDBMS数据可以进行无穷无尽的比较。关系数据库意味着你可以进行巨量比较,让分析师美梦成真。
END
其他比较受欢迎的内容,希望对你有帮助:
如何给老板发工资?这样做节税15.6万
一次通关!全网最全CPA综合备考攻略
考CPA有什么用?告诉你不一样的答案
我的5年CPA考证之旅
如何用回归分析预测未来?
看完点个赞,以后分享更多 。
-

女性安全期怎么算(安全期怎么算?)
#安全期是怎么算的,怀孕的时间有多少天# 女生正常月经周期为28天, 月 经周期分为月经期、排卵期和安全期。 -

什么是关系数据库(cpa数据库管理技巧)
最近,我正在读《深入浅出数据分析》这本书。 上期跟大家分享的书中主题是「 如何减小合理误差? 」。 -

踏板摩托外胎多少钱(建设工厂打造了一款时尚小踏板,售价7680元)
最近一年国内的踏板摩托车内卷很严重,许多知名的工厂都打造出了很多经典的踏板车。车子多样,外观时尚,动感 -

宝来联合灰汽车图片(大众新款宝来有望5月上市售9.88万元)
在紧凑级轿车市场上,大众宝来虽然名声不显,但销量还是非常不错的,凭借着出色的性能以及不错的性价比,月销1-2万辆都是常事,当然为 -

北京七环路规划图(小路互通全长3.51公里钢铁巨龙5天后通车)
进入倒计时!通州君获悉,北京大七环施工基本完成,钢铁巨龙5天后通车。 一、首环高速项目工程现浇箱梁全部完成 -

智能马桶排名(智能坐便器哪个牌子好?)
本文为《2021年家电爆款产品榜单》系列文章之智能坐便器篇。 2015年1 -

亚洲偶像盛典张翰(张翰节目录制《五十公里桃花坞——北京》,场面一度尴尬)
5月23日,综艺节目《五十公里桃花坞——北京》正式开播,张翰、宋丹丹、孟子义、辣目洋子等人作为嘉宾纷纷参与了此次节目的录制, -

各国国旗图片及名称(你见过哪些有特色的国徽?)
沙特 中东土豪的国徽十分简洁明朗,沙漠特色植物-椰枣树,绿色是沙漠地区人民最喜欢的颜色,下方两把阿 -

福特野马改装(福特野马改装vossenhf-)
动力就像男人的存款,你可以不用,但不能没有。这辆福特野马改装就是最好的诠释。 虽然小排量涡轮已经成为主 -

魂斗罗30条命手机版(《魂斗罗》的调命秘籍是什么?)
不知道当年的你,都用过哪些红白机游戏的秘籍呢? 估计很少吧!即使知道的也多半是经过同学之间口口相传的。很少有玩家能够